
Joining Strings in Python: A "Huh" Moment
I just love it when random conversations on Mastodon result in a “Huh, I didn’t know that”-moment. The other day I had one such moment about the Python programming language.
I’ve been writing Python code for the last 17 years, and quite a lot of it the last 7 years since it is now more or less my full time job. While I still learn things all the time about the language, I’ve started to get more curious about its quirks and surprises. CPython is the official implementation, but there are also others. This blog post is mainly about CPython.
Joining Strings in Python
Anyway. This whole thing started with a post where someone was showing a few neat tricks in Python, one involving changing line breaks in a piece of text using the standard str.join() method.
The straight forward way of joining strings in Python is to just add them to each other using the
+ operator. But Python strings are immutable, that is, you cannot change a string once it’s been
created. So adding them involves creating new strings all the time, which is inefficient when doing
so in long loops.
Instead, you can append the strings to a list. Then you simply join them all at the end using the
str.join() method. This is faster, and I use this a lot when I for instance generate HTML in
Python.
Python also has generators, which is a way of iterating over an object without first storing the
entire sequence in memory. This is efficient when you for instance want to loop over a sequence of
numbers, which can be done with the range() function. It knows what the next number is, so it
calculates it on the fly. It is also efficient if you want to read all lines from a file, one line
at a time.
Here’s an example where I remove all lines starting with # from a text file:
f = open("input_file.txt")
filtered_text = "\n".join(x for x in f if not x.startswith("#"))
This is the “text book solution”. What this does is to iterate over all lines x in the file, and
only include the ones not starting with #. These are then joined with an \n character between
them into a new string, where \n is the Unix line break character.
Generators vs. List Comprehension
Another nifty feature of Python is list comprehension, which is an inline notation for generating lists. It uses the same syntax as a generator, but inside a pair of brackets. So the above may instead be written as:
f = open("input_file.txt")
filtered_text = "\n".join([x for x in f if not x.startswith("#")])
Notice the extra brackets inside the parentheses, which is the only difference.
A lot of people new to Python may have learned about list comprehension but not always about generators, so the above code is quite common. But which one is the preferred solution in this specific case?
This whole conversation started when I pointed out on Mastodon that these brackets are redundant.
That’s when Trey Hunner, a Python educator, jumped in and
pointed out that this is not necessarily the case for str.join()!
Ok!
Let’s for a moment ignore both the join() part as well as the file reading, and assume we have a
variable data that is an iterable of some sort that contains a copy of the text we want to
process. Like, say another list or a generator.
You can create a new generator and list object from data thusly:
>>> a = (x for x in data)
>>> type(a)
generator
>>> b = [x for x in data]
>>> type(b)
list
Depending on what data actually is, this may not actually make any sense to do, but the point here is merely to illustrate. Here are some key points:
- The first code creates a “Generator”
object
a. A generator here will only return one value at a time, and extracts this from data only when requested. Ifdatais representingf(an open file), like above, this will only read one line from the file at a time, and not the entire file. This is memory efficient, although buffering will kick in and generally keep the text already read cached until you callf.close(). - The second code creates a regular Python list, which will read the entire content of
datainto that list, thus storing all of it in memory.
I have a stress test document I often use for testing my writing application. It is a single Markdown file containing the King James version of the bible. It is over 800 000 words long, so about 8–10 novels worth, or in the ball park of 2500–3000 pages.
For the sake of testing, I created a document where the text is repeated over and over until it adds up to 200 million words. Then I ran the following code to see how it uses my computer’s memory. I added a two second gap between each step so it’s easier to see the flat regions in the memory usage graph.
data = Path("long.txt").read_text().split()
sleep(2)
a = (x.lower() for x in data)
sleep(2)
b = [x.lower() for x in data]
sleep(2)
data.clear()
Here is the result:

A memory plot showing the memory usage for the four steps in the test.
My computer has 64 GB of RAM. Even though the text file is only about 1 GB, it expands to over 14 GB in memory when split into individual words. That is because a string in Python is an object with a fair bit of meta data in addition to the actual text characters it contains.
When the generator object a is created, nothing much happens. It just creates the object.
However, when the list b is created, it consumes another 14 GB of memory. I forced it to copy
each string by adding the lower() call which converts each word into a new lower case version of
itself. If I just used x as-is, it would instead create a pointer to the other string in data,
which would make my test less visual. I want to use all the RAMs!
Finally, the clear() call empties the data object, and a and b are also cleared in the end
since there is nothing further using these objects either.
When Python Behaves as Expected
Ok, so there are plenty of methods in Python that accept an iterable object as input. For instance, the all() function. What it does is evaluate each element in an iterable to check that they are all “True”, or “truthy”, which for strings means they are not empty:
data = Path("long.txt").read_text().split()
sleep(2)
a = all(x.lower() for x in data)
sleep(2)
b = all([x.lower() for x in data])
sleep(2)
data.clear()
As expected, the memory usage is pretty much identical to the first test:

Memory usage for a generator and list object passed to all().
This means that the generator is also memory efficient here. There is no visible bump at this scale, only for the list version.
Now, for the third test, lets use join(), which is after all the topic of this post. This code
will join all words with a space between them:
data = Path("long.txt").read_text().split()
sleep(2)
a = " ".join(x.lower() for x in data)
sleep(2)
b = " ".join([x.lower() for x in data])
sleep(2)
data.clear()
And here’s the memory profile:

Memory usage for a generator and list object passed to str.join().
As you can see, there are now two clear bumps of equal height! There is no longer a benefit from using the generator. If you look closely, the generator also takes a little more time than the list version.
What the hell is going on here?
A Quirk of the CPython Join Implementation
First, let’s look more closely at the time used. I ran a timing test of each approach in an iPython interactive session. This code joins all words longer than one character, but it does not force a copy of each word, so we get a clearer picture of the join process itself.
In [15]: %timeit " ".join(a for a in data if len(a) > 1)
7.82 s ± 4.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [16]: %timeit " ".join([a for a in data if len(a) > 1])
6.76 s ± 5.99 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
As you can clearly see, the generator approach is about 16% slower than list comprehension. This is pretty consistent across all tests I’ve done on my system at different data sizes.
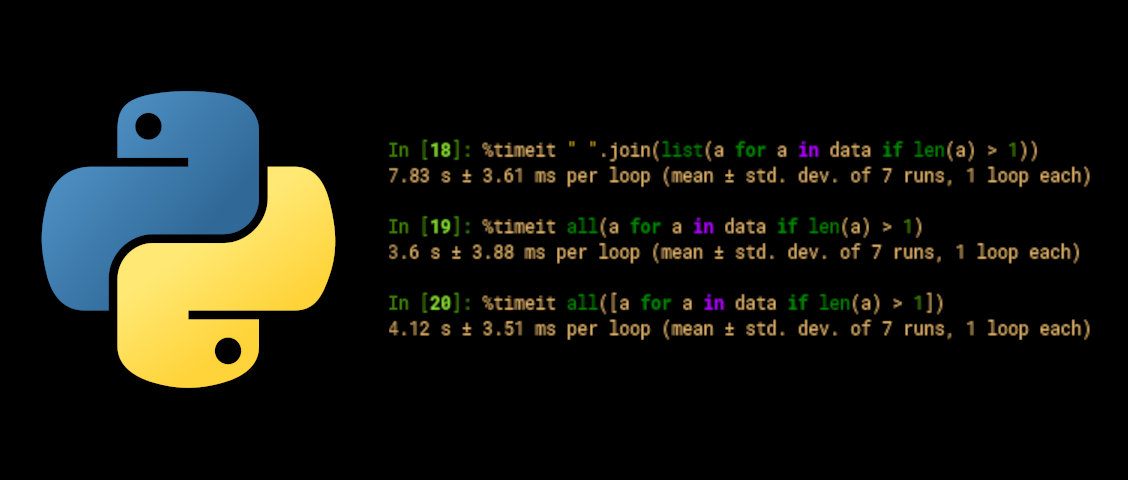
Running the same test for all() gives the expected result:
In [19]: %timeit all(a for a in data if len(a) > 1)
3.6 s ± 3.88 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [20]: %timeit all([a for a in data if len(a) > 1])
4.12 s ± 3.51 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Here, the list comprehension is instead 14% slower than the generator.
Here’s what’s actually going on:
This is what Trey Hunner was hinting at in this Mastodon post:
I do know that it’s not possible to do 2 passes over a generator (since it’d be exhausted after the first pass) so from my understanding, the generator version requires an extra step of storing all the items in a list first.
While the str.join() method accepts a generator object as input, presumably to be consistent with
other similar functions and methods like all() etc, it cannot actually use the generator. So it
converts it.
Effectively, this is what it does when you pass it a generator object:
In [18]: %timeit " ".join(list(a for a in data if len(a) > 1))
7.83 s ± 3.61 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
As you can see from the timing, this is pretty much identical to the previous test.
The reason for this is, as Trey said, that the str.join() implementation in CPython uses a two
pass approach. It first calculates how big the result should be and allocates the memory, and then
joins the text. It’s not really all that mysterious, but it was surprising to me at least, and
clearly to many others when I posted about it on Mastodon.
If you’re wondering, the magic happens in the PyUnicode_Join function in the CPython implementation. Notice especially this bit:
fseq = PySequence_Fast(seq, "can only join an iterable");
if (fseq == NULL) {
return NULL;
}
This is what ensures that the input sequence seq is a sequence (list in this context) and not a
generator. You can follow the rabbit hole of subsequent function calls all the way down if you
wish. There are quite a lot of them, but in the end there is a loop that calls the iterator from
the generator object and appends the results to a list.
Calling each iteration of the generator is slower than directly appending them like the list comprehension method does, so I’m pretty certain this is where the performance difference comes from.
The difference between
[a for a in data]
and
list(a for a in data)
is subtle, but there is a difference. The first is optimised for generating a list directly, and does not create any generator bytecode. The second builds a list from a generator, and at least in Python 3.11 bytecode, creates the generator and then populates the list from it.
Mostly Just CPython?
This is very CPython specific, and as Corbin on Mastodon pointed out, does not hold true for PyPy, another Python implementation:
Apples to apples on medium-length input, fits in RAM, Python 3.10:
- PyPy, list comp: ~610ms
- CPython, no list comp: ~350ms
- CPython, list comp: ~230ms
- PyPy, no list comp: ~110ms
At the end of the day, using the generator notation for str.join() will likely not make much of a
difference unless it’s performance critical. So I think I may still recommend this notation when
there are no other concerns to consider. In most use cases where I use str.join() in this way,
I do so because I already have a large list of text generated, so then the consideration here
doesn’t even apply.
Anyway, this was a fun topic to dig into at least, and I stayed up way too late that evening with it, and had to pay for that the next morning.
Changes
Updated 2024-06-16: Removed .readlines() from example, and rephrase point about mutability of
strings and lists for clarity.
Comments
You can use your Mastodon account to comment on this post by replying to this thread.
Alternatively, you can copy and paste the URL below into the search field of your Fediverse app or the web interface of your Mastodon server.
:
The Mastodon integration is based on the implementation by Carl Schwan.